Appearance
Seata 常见面试题
Seata(Simple Extensible Autonomous Transaction Architecture)是阿里巴巴开源的分布式事务解决方案,聚焦微服务场景下的高可用、高性能事务问题。由于其支持多模式(AT/TCC/SAGA/XA)、低侵入性和活跃社区,成为分布式事务面试的高频考点。 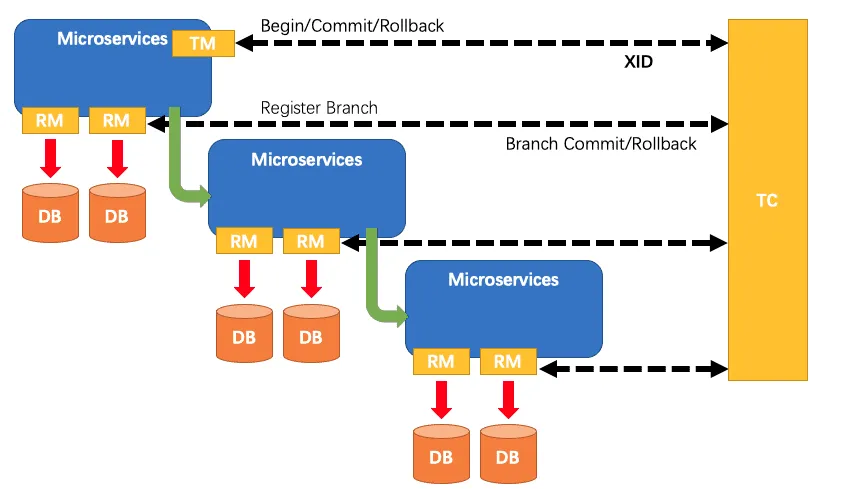
1. 请解释Seata的核心概念与组件,以及它们的交互流程
Seata的核心是分阶段提交+全局事务协调,核心组件包括TC(Transaction Coordinator,事务协调器)、TM(Transaction Manager,事务管理器)、RM(Resource Manager,资源管理器),三者协同完成分布式事务。
核心概念
- 全局事务(Global Transaction):跨微服务的事务,由TM发起,包含多个分支事务。
- 分支事务(Branch Transaction):微服务内的本地事务,是全局事务的子集。
- XID(Global Transaction ID):全局事务的唯一标识,贯穿整个事务生命周期,用于关联全局与分支事务。
核心组件
TC(事务协调器)
- 核心角色:维护全局事务与分支事务的状态,协调全局事务的提交/回滚。
- 职责:生成XID、接收TM的全局事务请求、接收RM的分支注册、通知RM执行提交/回滚。
- 部署形式:独立的Seata Server集群(高可用)。
TM(事务管理器)
- 核心角色:发起并控制全局事务的边界(开始、提交、回滚)。
- 职责:向TC申请开启全局事务(获取XID)、将XID传递给下游微服务、触发全局提交/回滚。
- 存在形式:嵌入在业务微服务中(如Spring Cloud中的
@GlobalTransactional注解)。
RM(资源管理器)
- 核心角色:管理本地资源(如数据库连接),执行分支事务的提交/回滚,并向TC注册分支事务。
- 职责:代理数据源(如
DataSourceProxy)、生成undo log(AT模式)、接收TC的分支指令。 - 存在形式:嵌入在业务微服务中,与数据库交互。
组件交互流程(以AT模式为例)
- TM发起全局事务:TM向TC申请开启全局事务,TC生成XID并返回给TM。
- XID传递:TM通过RPC(如Feign)将XID传递给下游微服务(RM),下游微服务通过
ThreadLocal存储XID。 - RM注册分支事务:每个RM执行本地SQL,生成undo log,提交本地事务(第一阶段),并向TC注册分支事务(关联XID与分支ID)。
- 全局决策:TM根据业务执行结果,向TC发起全局提交/回滚请求。
- 分支执行:TC通知所有RM执行分支提交/回滚(第二阶段):
- 提交:RM删除undo log;
- 回滚:RM执行undo log恢复数据。
2. Seata支持哪些事务模式?请分别说明它们的原理、适用场景与优缺点
Seata提供4种核心事务模式,覆盖不同场景的分布式事务需求:
1. AT模式(Auto Transaction,自动事务)
- 核心思想:无侵入的分布式事务,基于undo log + 本地事务提交实现两阶段提交(2PC)。
- 原理流程:
- 第一阶段(Try):
- RM代理数据源,拦截SQL执行;
- 解析SQL,查询before image(修改前的数据);
- 执行SQL,生成after image(修改后的数据);
- 生成undo log(包含before image、表结构、主键等),插入
undo_log表; - 提交本地事务(释放数据库锁);
- 向TC注册分支事务。
- 第二阶段(Commit/Rollback):
- Commit:TC通知RM删除undo log(无风险,因为本地已提交);
- Rollback:TC通知RM执行undo log(用before image恢复数据),然后删除undo log。
- 第一阶段(Try):
- 适用场景:
- 基于关系型数据库(MySQL、Oracle等)的微服务;
- 希望低侵入(无需修改业务代码)的场景。
- 优缺点:
- 优点:无侵入、性能高(本地事务提前提交,释放数据库锁);
- 缺点:依赖数据库事务、不支持非关系型数据库、需要生成undo log。
2. TCC模式(Try-Confirm-Cancel)
- 核心思想:手动实现补偿逻辑,将事务拆分为“尝试(Try)- 确认(Confirm)- 取消(Cancel)”三个阶段。
- 原理流程:
- Try:尝试执行业务(如冻结库存、预留资金),确保资源可用且幂等;
- Confirm:确认执行(如扣减库存、扣款),仅在Try成功后执行;
- Cancel:取消执行(如解冻库存、退还资金),仅在Try失败后执行。
- 适用场景:
- 非关系型数据库(Redis、MongoDB);
- 第三方服务(如支付接口、短信接口);
- 需要自定义补偿逻辑的场景。
- 优缺点:
- 优点:灵活(支持任意场景)、性能高(无undo log);
- 缺点:开发量大(需手动实现Try/Confirm/Cancel)、需保证幂等性。
3. SAGA模式
- 核心思想:长事务解决方案,基于状态机+补偿链实现最终一致性。
- 原理流程:
- 正向流程:按顺序执行各个微服务的业务逻辑(如“下单→扣库存→支付→发货”);
- 补偿流程:若某一步失败,反向执行补偿操作(如“发货失败→退款→恢复库存→取消订单”)。
- 适用场景:
- 长链路事务(如电商下单、物流履约);
- 异步、高并发场景;
- 允许中间状态的业务(如“订单已创建但未支付”)。
- 优缺点:
- 优点:支持长事务、异步执行、无锁;
- 缺点:最终一致性(不保证强一致)、需处理幂等与重试。
4. XA模式
- 核心思想:传统2PC的实现,依赖数据库的XA协议(如MySQL的
XA START/XA END)。 - 原理流程:
- 第一阶段(Prepare):RM执行SQL但不提交,向TC汇报准备状态;
- 第二阶段(Commit/Rollback):TC根据所有RM的准备状态,通知执行提交/回滚。
- 适用场景:
- 要求强一致性的场景(如金融核心系统);
- 兼容传统XA协议的数据库。
- 优缺点:
- 优点:强一致、数据库原生支持;
- 缺点:性能低(第一阶段需持有数据库锁)、侵入性高(需修改数据源配置)。
模式对比总结
| 维度 | AT模式 | TCC模式 | SAGA模式 | XA模式 |
|---|---|---|---|---|
| 侵入性 | 低(无代码修改) | 高(手动写补偿) | 中(需定义状态机) | 中(改数据源) |
| 一致性 | 强一致 | 强一致 | 最终一致 | 强一致 |
| 性能 | 高 | 高 | 极高 | 低 |
| 适用场景 | 关系型数据库 | 自定义/第三方服务 | 长事务/异步 | 强一致需求 |
3. Seata AT模式的undo log是如何生成的?它的作用是什么?
undo log是AT模式的核心,用于在全局回滚时恢复数据。
undo log的生成流程
AT模式通过代理数据源(DataSourceProxy)拦截SQL执行,生成undo log:
- 解析SQL:拦截
PreparedStatement的执行,解析SQL的类型(如UPDATE/DELETE/INSERT)、表名、主键、修改的字段。 - 查询Before Image:执行SQL前,根据主键查询修改前的数据(如
SELECT * FROM t_order WHERE id = ? FOR UPDATE,加行锁防止脏写)。 - 执行SQL:执行用户的SQL,修改数据。
- 查询After Image:执行SQL后,再次查询修改后的数据(仅针对UPDATE/DELETE,INSERT无After Image)。
- 生成undo log:将Before Image、After Image、表结构、XID、分支ID等信息序列化为JSON,插入
undo_log表。
undo log的结构
undo_log表的核心字段:
branch_id:分支事务ID;xid:全局事务ID;rollback_info:序列化后的undo log(包含Before Image、表名、主键等);log_status:日志状态(0:有效,1:已删除)。
undo log的作用
- 回滚:全局回滚时,RM解析
rollback_info,生成反向SQL(如UPDATE的反向是恢复Before Image),执行反向SQL恢复数据。 - 幂等:回滚时检查
log_status,避免重复执行。
4. Seata AT模式如何保证隔离级别?全局锁与本地锁的区别是什么?
AT模式的隔离级别是读已提交(Read Committed),通过本地锁+全局锁共同保证。
隔离级别的实现
- 本地锁:数据库的行锁(如InnoDB的
FOR UPDATE),保证本地事务内的并发安全(第一阶段执行SQL时加锁,本地事务提交后释放)。 - 全局锁:TC维护的分布式锁,关联XID与数据库行(如“t_order:id=1”),保证全局事务的并发安全。
- 第一阶段:RM提交本地事务后,向TC申请全局锁(持有至第二阶段完成);
- 第二阶段:全局提交/回滚后,TC释放全局锁。
全局锁与本地锁的区别
| 维度 | 本地锁(数据库) | 全局锁(Seata TC) |
|---|---|---|
| 作用范围 | 本地事务内的并发控制 | 全局事务间的并发控制 |
| 持有时间 | 本地事务提交后释放 | 全局事务完成后释放 |
| 实现方式 | 数据库原生(如InnoDB行锁) | Seata TC的内存/数据库存储 |
| 解决的问题 | 本地脏写 | 分布式脏写 |
例子:避免分布式脏写
假设两个全局事务A和B,都要修改t_order的id=1行:
- 事务A的RM执行SQL,加本地锁,提交本地事务,申请全局锁(成功);
- 事务B的RM执行SQL,加本地锁(成功),但申请全局锁时发现已被A持有,阻塞等待;
- 事务A全局提交,释放全局锁;
- 事务B获得全局锁,提交本地事务,完成修改。
通过全局锁,避免了两个全局事务同时修改同一行(分布式脏写)。
5. 什么是“悬挂”和“空回滚”?Seata如何处理这些问题?
在TCC/SAGA模式中,由于网络延迟或重试,可能出现悬挂(Cancel在Try之前执行)和空回滚(Cancel在Try失败后执行)的问题。
1. 悬挂(Hanging)
- 定义:Cancel操作在Try操作之前执行(如Try因网络超时未到达,而Cancel先到达)。
- 危害:Try未执行,Cancel操作会修改不存在的资源(如解冻未冻结的库存)。
- Seata的处理:
TC在执行Cancel前,检查分支事务是否已注册(Try操作会向TC注册分支)。若未注册,则直接返回,不执行Cancel。
2. 空回滚(Null Rollback)
- 定义:Try操作执行失败(如抛出异常),但全局事务发起回滚,导致Cancel操作执行。
- 危害:Try未成功,Cancel操作会重复补偿(如多次解冻库存)。
- Seata的处理:
Try操作失败时,不向TC注册分支事务。全局回滚时,TC无该分支的记录,不会通知RM执行Cancel。
6. Seata如何保证幂等性?
分布式事务中,重试(如网络超时)是常见场景,必须保证同一请求多次执行的结果一致。Seata通过以下方式保证幂等:
1. 全局事务的幂等
- XID唯一性:每个全局事务的XID唯一,TM重复发起全局事务时,TC会识别并拒绝。
- 状态机控制:TC维护全局事务的状态(初始化→提交中→已提交/已回滚),重复的提交/回滚请求会直接返回最终状态。
2. 分支事务的幂等
- 分支ID唯一性:每个分支事务的
XID+Branch ID唯一,RM重复执行分支指令时,会检查undo_log或分支状态,避免重复操作。 - TCC模式的幂等:要求业务方在Try/Confirm/Cancel方法中实现幂等(如用
request_id或业务唯一键做校验)。
例子:TCC的幂等实现
java
@TccAction(
name = "freezeStock",
commitMethod = "confirmFreeze",
rollbackMethod = "cancelFreeze"
)
public boolean tryFreezeStock(Long productId, Integer num, String requestId) {
// 检查requestId是否已处理(如存Redis)
if (redis.exists("freeze:" + requestId)) {
return true;
}
// 冻结库存
stockDao.freeze(productId, num);
// 记录requestId
redis.set("freeze:" + requestId, "processed", 3600);
return true;
}7. Seata的高可用如何实现?集群部署需要注意什么?
Seata的高可用依赖TC集群与注册中心/配置中心,确保单点故障不影响全局事务。
1. 高可用架构
- TC集群:部署多台Seata Server,通过注册中心(如Nacos、Eureka)实现服务发现;
- 注册中心:RM/TM通过注册中心获取TC集群地址,实现负载均衡;
- 配置中心:存储全局配置(如事务组映射、日志存储方式),集群共享配置;
- 事务日志存储:TC的事务日志需存储在共享存储(如MySQL、Redis)中,确保集群节点间状态一致。
2. 集群部署注意事项
- 注册中心配置:所有TC节点需注册到同一个注册中心(如Nacos的
serverAddr一致); - 事务组映射:客户端需配置
service.vgroup_mapping.{app-name} = {group-name},TC需配置service.group_mapping.{group-name} = {tc-cluster-list}(如group1=127.0.0.1:8091,127.0.0.1:8092); - 日志存储:生产环境建议用数据库(如MySQL)存储事务日志,避免文件存储的单点问题;
- 负载均衡:RM/TM通过注册中心获取TC集群地址,默认使用随机负载均衡,可自定义(如轮询)。
8. Seata与Spring Cloud集成的步骤是什么?需要注意哪些问题?
Seata与Spring Cloud的集成非常便捷,核心是代理数据源与全局事务注解。
集成步骤
- 部署Seata Server:参考官方文档部署TC集群,配置注册中心(如Nacos)。
- 引入依赖:在Spring Cloud项目中添加Seata starter:xml
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> </dependency> - 配置Seata客户端:在
application.yml中配置注册中心、事务组等:yamlspring: cloud: alibaba: seata: tx-service-group: my_tx_group # 事务组名称 seata: registry: type: nacos nacos: server-addr: 127.0.0.1:8848 namespace: seata_namespace config: type: nacos nacos: server-addr: 127.0.0.1:8848 - 代理数据源:用Seata的
DataSourceProxy替换原数据源(关键!否则AT模式无法生成undo log):java@Configuration public class DataSourceConfig { @Bean @ConfigurationProperties(prefix = "spring.datasource") public DataSource rawDataSource() { return new DruidDataSource(); } @Bean public DataSourceProxy dataSourceProxy(DataSource rawDataSource) { return new DataSourceProxy(rawDataSource); } @Bean public SqlSessionFactory sqlSessionFactory(DataSourceProxy dataSourceProxy) throws Exception { SqlSessionFactoryBean factory = new SqlSessionFactoryBean(); factory.setDataSource(dataSourceProxy); return factory.getObject(); } } - 标记全局事务:在全局事务发起方的方法上添加
@GlobalTransactional注解:java@Service public class OrderService { @Autowired private OrderDao orderDao; @Autowired private StockFeignClient stockFeignClient; @GlobalTransactional(name = "createOrder", rollbackFor = Exception.class) public void createOrder(Order order) { // 1. 插入订单(本地事务) orderDao.insert(order); // 2. 调用库存服务扣减库存(分布式调用,传递XID) stockFeignClient.reduceStock(order.getProductId(), order.getNum()); } }
注意事项
- 数据源代理:必须用
DataSourceProxy代理原数据源,否则AT模式无法拦截SQL生成undo log; - XID传递:确保Feign/RestTemplate等RPC框架传递XID(Seata starter已自动处理);
- 事务组一致性:客户端的
tx-service-group需与TC的group_mapping配置一致; - undo_log表:AT模式需要在数据库中创建
undo_log表(参考Seata官方文档)。
9. Seata的事务组(Transaction Group)是什么?有什么作用?
事务组是Seata中的逻辑分组,用于将一组微服务与对应的TC集群关联,实现负载均衡与隔离。
作用
- 负载均衡:不同的事务组可以对应不同的TC集群,分散流量;
- 隔离性:不同业务线的事务组相互隔离,避免互相影响(如电商的“订单组”与“支付组”用不同的TC集群);
- 灵活性:可以针对不同事务组配置不同的参数(如超时时间、重试次数)。
配置示例
- 客户端配置(
application.yml):yamlspring: cloud: alibaba: seata: tx-service-group: order_tx_group # 订单服务的事务组 - TC配置(
registry.conf):yamlservice: group_mapping: order_tx_group: 127.0.0.1:8091,127.0.0.1:8092 # 订单组对应的TC集群 pay_tx_group: 127.0.0.1:8093,127.0.0.1:8094 # 支付组对应的TC集群
11. Seata AT模式中,本地事务提前提交会导致脏数据吗?
不会。因为AT模式通过全局锁保证了分布式事务的原子性:
- 本地事务提交后,RM会向TC申请全局锁,持有至全局事务完成;
- 其他全局事务要修改同一行数据,必须等待全局锁释放;
- 若全局事务回滚,RM会执行undo log恢复数据,此时全局锁未释放,其他事务无法修改,避免脏数据。
12. Seata SAGA模式如何处理幂等与重试?
SAGA模式是异步的,必须处理幂等(重复执行同一操作)与重试(失败后重新执行):
1. 幂等处理
- 业务唯一键:每个SAGA步骤生成唯一键(如
order_id+step),执行前检查是否已处理; - 状态机标记:SAGA状态机维护每个步骤的状态(未执行→执行中→成功/失败),避免重复执行。
2. 重试处理
- 正向重试:若某一步失败(如网络超时),可重试该步骤(需保证幂等);
- 补偿重试:若补偿步骤失败,需重试直到成功(如“退款”操作必须执行成功)。
13. Seata的配置中心与注册中心有什么区别?
- 配置中心:存储Seata的全局配置(如TC地址、事务模式、undo log参数),支持动态更新(如Nacos的配置推送);
- 注册中心:存储Seata的服务地址(如TC集群的IP:Port),支持服务发现与负载均衡。
14. Seata AT模式中,undo log表的索引如何优化?
undo_log表的核心索引是**xid+branch_id**(唯一索引),用于快速查询与删除undo log:
sql
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`) -- 核心索引
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;优化建议:
- 定期清理已提交的undo log(Seata会自动删除,但可配置
undo.log.delete.period调整周期); - 避免
undo_log表的数据量过大(如分库分表)。
15. Seata生产环境中常见的问题与解决方法
1. 全局锁等待超时
- 现象:RM申请全局锁时超时,抛出
GlobalLockWaitTimeoutException; - 原因:某个全局事务持有全局锁时间过长(如慢SQL);
- 解决:
- 优化慢SQL(如加索引);
- 调整全局锁超时时间(
client.rm.lock.retryTimeout,默认3000ms); - 检查是否有长事务(如SAGA模式的长时间未完成)。
2. undo log表不存在
- 现象:AT模式执行时抛出
Table 'undo_log' doesn't exist; - 原因:未在数据库中创建
undo_log表; - 解决:参考Seata官方文档创建
undo_log表(注意引擎是InnoDB)。
3. XID未传递
- 现象:下游微服务未获取到XID,导致分支事务未注册;
- 原因:RPC框架未传递
XID(如Feign未配置拦截器); - 解决:Seata starter已自动配置Feign/RestTemplate的拦截器,确保依赖正确。
4. TC集群节点不一致
- 现象:部分TC节点无法处理事务;
- 原因:TC节点的配置不一致(如事务组映射不同);
- 解决:确保所有TC节点的
registry.conf与file.conf配置一致。
总结
Seata的面试题核心围绕模式原理、组件交互、实践细节。掌握这些问题,不仅能应对面试,更能在实际项目中正确使用Seata解决分布式事务问题。关键是要理解每种模式的适用场景,并结合业务需求选择合适的方案(如AT模式适合大多数关系型数据库场景,TCC适合第三方服务,SAGA适合长事务)。