Appearance
一致性哈希算法
要理解一致性哈希算法,我们需要先回到它要解决的核心问题,再逐步拆解其设计原理、关键特性与实践价值。 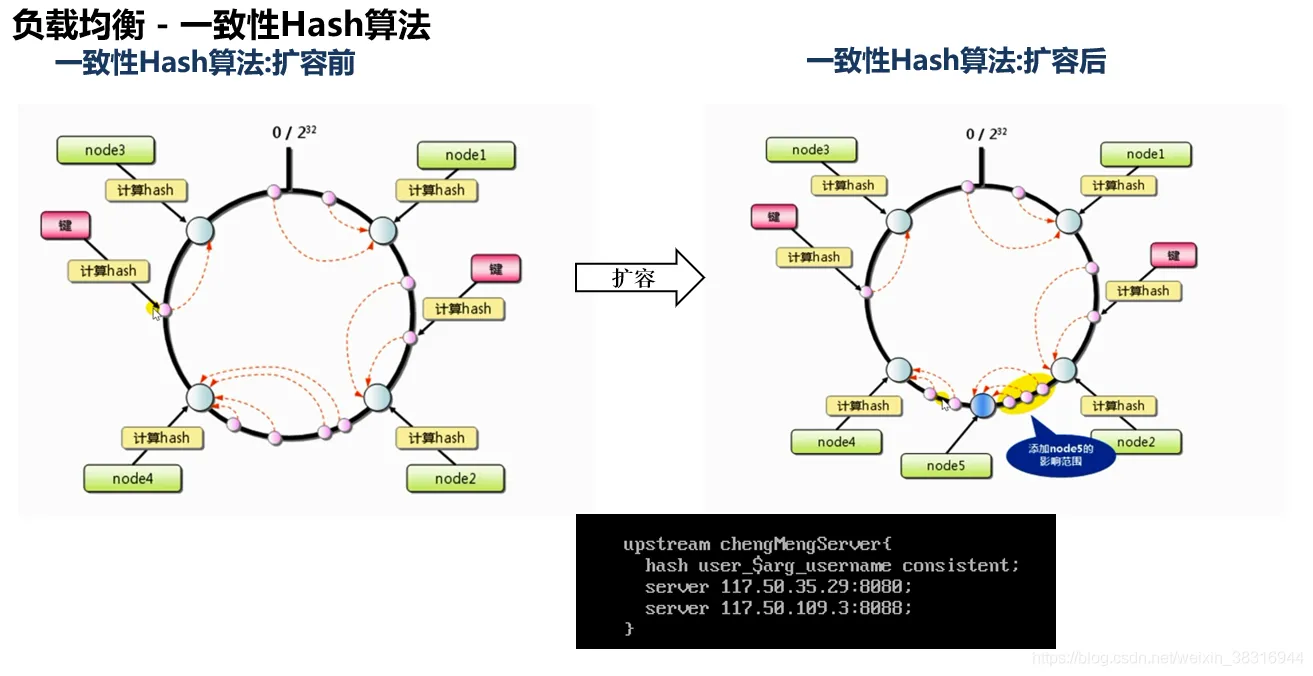
一、为什么需要一致性哈希?——传统哈希的痛点
在分布式系统(如缓存、数据库分库分表)中,我们常需将数据均匀分配到多个节点(服务器/分片)。传统方案用模运算(hash(key) % n,n为节点数),但存在致命问题:
假设我们有3个缓存节点(n=3),数据key的哈希值为5,则5%3=2,对应节点2。若新增1个节点(n=4),则5%4=1,数据会被重新路由到节点1——所有数据的映射关系都被打乱!这会导致:
- 缓存大面积失效(缓存命中率暴跌);
- 数据库压力骤增(所有请求穿透到DB);
- 节点扩容/缩容时数据迁移量极大(100%数据需重新分配)。
一致性哈希的目标:节点增减时,仅需迁移少量数据,同时保证数据均匀分布。
二、一致性哈希的核心原理
一致性哈希的设计可以概括为4个核心步骤,我们用“分布式缓存”场景举例说明:
1. 构建“哈希环”
将哈希空间(哈希函数的输出范围)映射为一个闭环(环形结构)。例如,常用的哈希函数(如MD5、MurmurHash)输出是32位无符号整数,因此哈希环的范围是0 ~ 2³²-1(约42亿个位置)。
2. 映射节点到哈希环
将物理节点(如缓存服务器、数据库分片)通过哈希函数映射到环上的某个位置。
例如:
- 服务器A(IP: 192.168.0.1)的哈希值为
10000; - 服务器B(IP: 192.168.0.2)的哈希值为
20000; - 服务器C(IP: 192.168.0.3)的哈希值为
30000。
3. 映射数据到节点
对于数据key(如user:100),计算其哈希值,然后在哈希环上顺时针查找最近的节点,该节点即为数据的存储位置。
例如:
- 数据
user:100的哈希值为15000; - 顺时针查找最近的节点是B(哈希值
20000),因此数据存到B。
4. 节点增减的处理(核心优势)
当新增/删除节点时,仅需迁移相邻节点的数据,而非全部:
案例1:新增节点D
假设新增服务器D,哈希值为18000(位于A和B之间)。此时:
- 原哈希值在
10000~18000之间的数据(如user:99哈希值12000),原路由到B,现在顺时针最近的节点变为D; - 仅需迁移A到D之间的数据(约1/4总数据量),其他数据的映射不变。
案例2:删除节点B
若节点B故障,需删除:
- 原路由到B的数据(哈希值
10000~20000),顺时针最近的节点变为C; - 仅需迁移B到C之间的数据(约1/3总数据量),其他数据不受影响。
三、解决“数据分布不均”——虚拟节点
上述基础方案存在一个问题:物理节点数量较少时,数据可能集中在少数节点(如2个节点的哈希位置很近,导致90%数据落到其中一个节点)。
虚拟节点(Virtual Node)是解决这个问题的关键:
- 为每个物理节点创建多个虚拟节点(如10个);
- 虚拟节点也映射到哈希环上,但最终会指向对应的物理节点;
- 数据先路由到虚拟节点,再映射到物理节点。
示例:虚拟节点的作用
假设物理节点A、B、C各对应2个虚拟节点:
- A的虚拟节点:
A1(哈希5000)、A2(哈希15000); - B的虚拟节点:
B1(哈希25000)、B2(哈希35000); - C的虚拟节点:
C1(哈希45000)、C2(哈希55000)。
数据user:100的哈希值为22000,顺时针最近的虚拟节点是B1(哈希25000),对应物理节点B。
效果:虚拟节点让物理节点的哈希分布更“密集”,数据会均匀分散到各个虚拟节点,最终实现物理节点的负载均衡。
四、一致性哈希的核心特性
对比传统哈希,一致性哈希具备以下关键优势:
| 特性 | 说明 |
|---|---|
| 单调性 | 新增/删除节点时,仅迁移相邻数据,不改变其他数据的映射关系 |
| 分散性 | 数据均匀分布在节点上(通过虚拟节点优化) |
| 负载均衡 | 虚拟节点让物理节点的负载更均衡 |
| 容错性 | 单个节点故障时,仅影响其负责的数据,其他节点正常服务 |
| 扩展性 | 节点增减时,迁移数据量小,支持动态扩容 |
五、一致性哈希的实践应用
一致性哈希是分布式系统的基础工具,广泛用于以下场景:
1. 分布式缓存(如Redis Cluster)
Redis Cluster使用哈希槽(Slot)机制,本质是一致性哈希的变种:
- 共
16384个哈希槽(对应哈希环的位置); - 每个Redis节点负责一部分槽(如节点A负责槽
0~5000); - 数据
key的哈希值对16384取模,得到对应的槽,再路由到节点。
优势:槽的迁移比数据迁移更高效,扩容时仅需迁移槽,无需修改数据映射。
2. 数据库分库分表(如ShardingSphere)
ShardingSphere支持一致性哈希分片策略,通过虚拟节点实现数据均匀分布:
yaml
spring:
shardingsphere:
rules:
sharding:
tables:
order: # 订单表
actual-data-nodes: ds${0..3}.order${0..1} # 4个数据源,每个数据源2张表
table-strategy:
consistent-hash: # 一致性哈希分片
sharding-column: order_id # 分片键(订单ID)
sharding-algorithm-name: order-consistent-hash
sharding-algorithms:
order-consistent-hash:
type: CONSISTENT_HASH
props:
virtual-nodes: 10 # 每个物理节点对应10个虚拟节点效果:订单数据按order_id的哈希值均匀分布到4个数据源,扩容时仅需迁移少量数据。
3. 负载均衡(如Nginx的一致性哈希模块)
Nginx的ngx_http_upstream_consistent_hash_module模块,用一致性哈希实现请求的负载均衡:
- 将客户端IP或请求URI哈希到环上;
- 路由到最近的后端服务器;
- 新增服务器时,仅需迁移部分请求,保证会话粘滞(Session Sticky)。
六、一致性哈希的局限性与优化
1. 局限性
- 虚拟节点数量依赖:需足够多的虚拟节点才能保证负载均衡(如10~100个/物理节点);
- 哈希函数依赖:若哈希函数分布不均,会导致数据倾斜(需选择MurmurHash等高性能、均匀的哈希函数);
- 高可用需额外机制:一致性哈希仅解决数据分布问题,节点故障时需依赖主从复制、副本集等机制保证数据不丢失。
2. 优化方向
- 动态虚拟节点:根据物理节点的性能(CPU/内存)调整虚拟节点数量(性能强的节点对应更多虚拟节点);
- 分层一致性哈希:将哈希环分为多个层级,解决跨数据中心的节点分布问题;
- 带权重的一致性哈希:为物理节点分配权重(如节点A权重2,节点B权重1),虚拟节点数量按权重比例分配,实现更精细的负载均衡。
七、总结
一致性哈希的核心是用环形结构+虚拟节点解决传统哈希的痛点,实现:
- 节点增减时小量数据迁移;
- 数据均匀分布;
- 系统高扩展性。
它是分布式系统中分片策略的基石,理解其原理能帮你更好地设计缓存、数据库分库分表等系统。
一句话总结:
一致性哈希将节点和数据映射到环形空间,数据找顺时针最近的节点,虚拟节点解决分布不均,最终实现“增减节点不打乱全局,仅动相邻数据”。