Appearance
CQRS架构
要理解CQRS(Command Query Responsibility Segregation,命令查询责任分离),我们需要先跳出传统CRUD的思维定式,从「职责分离」的核心逻辑入手——它本质是将「改变系统状态的操作」和「获取系统状态的操作」彻底拆开,用两套独立的模型和流程处理。
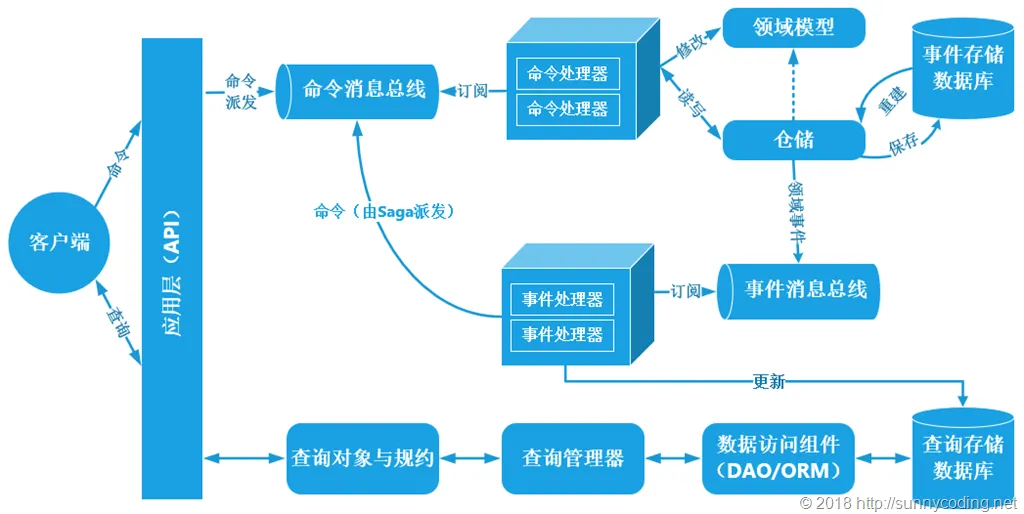
一、为什么需要CQRS?——传统CRUD的痛点
在传统的CRUD架构中,我们通常用同一个数据模型处理「写(Create/Update/Delete)」和「读(Read)」操作。比如一个用户服务,User实体既要处理「创建用户」的校验逻辑(如密码强度、手机号唯一性),又要处理「查询用户详情」的字段组装(如关联订单、地址)。这种耦合会导致三个核心问题:
- 性能冲突:写操作需要事务、锁、数据一致性,读操作需要高效、多维度查询(如联合索引、分页),同一个模型无法同时优化两种场景;
- 复杂度上升:为了满足读需求,往往要在写模型中加冗余字段或关联查询,导致实体变得臃肿;
- 扩展性不足:当读流量远大于写流量时(如电商商品详情页),无法单独扩容读侧资源,只能整体升级数据库,成本极高。
CQRS的出现,就是为了解耦读写职责,让写侧专注于「正确性」,读侧专注于「效率」。
二、CQRS的核心概念:Command与Query
CQRS的灵魂是区分「命令」和「查询」,两者有着本质的不同:
1. Command(命令):改变状态的操作
- 定义:** imperativ(命令式)操作,目的是修改系统状态**(如创建、更新、删除),没有返回值(或仅返回操作结果状态,如成功/失败)。
- 核心特征:
- 幂等性:同一个命令执行多次,结果必须一致(比如
CreateOrder用订单ID作为唯一标识,重复执行不会创建多个订单); - 单一职责:一个命令只做一件事(如
UpdateUserPassword而不是UpdateUserInfoAndPassword); - 需验证:执行前必须通过业务规则校验(如密码强度、库存是否充足)。
- 幂等性:同一个命令执行多次,结果必须一致(比如
- 例子:
CreateUserCommand(创建用户)、CancelOrderCommand(取消订单)、DeductInventoryCommand(扣减库存)。
2. Query(查询):获取状态的操作
- 定义:** declarative(声明式)操作,目的是读取系统状态**,不改变任何数据,返回具体的查询结果。
- 核心特征:
- 无副作用:执行查询不会修改数据库、缓存或任何系统状态;
- 只读优化:可以自由使用缓存、反规范化(Denormalization)、索引等手段提升查询效率;
- 按需组装:返回的数据结构可以完全贴合前端需求(如
UserProfileQuery返回用户昵称、头像、等级,无需关联用户的密码、创建时间等敏感字段)。
- 例子:
GetUserByIdQuery(根据ID查用户)、ListOrdersByUserAndDateQuery(根据用户和时间查订单列表)、GetProductStockQuery(查商品库存)。
三、CQRS的基础架构:两套模型,各自为战
CQRS的架构核心是分离「写模型」和「读模型」,并通过「命令处理器」和「查询处理器」分别处理两类操作。以下是最简架构示意图:
[客户端] → 发送Command → [Command Handler] → 执行业务逻辑 → 更新[写模型](如MySQL)
[客户端] → 发送Query → [Query Handler] → 查询[读模型](如Elasticsearch/Redis) → 返回结果1. 写侧:Command Handler与写模型
- Command Handler:负责接收Command,执行业务规则校验(如用户是否存在、库存是否足够)、领域逻辑(如扣减库存、生成订单号),最终更新「写模型」。
例如处理CreateOrderCommand的流程:- 校验用户ID是否有效;
- 校验商品库存是否充足;
- 生成唯一订单号;
- 向写模型(MySQL的
orders表)插入订单记录; - 返回操作结果(成功/失败原因)。
- 写模型:通常是关系型数据库(如MySQL、PostgreSQL),因为需要事务支持和强一致性,保证写操作的正确性。
2. 读侧:Query Handler与读模型
- Query Handler:负责接收Query,从「读模型」中查询数据,无需复杂业务逻辑,专注于高效返回结果。
例如处理GetOrderHistoryByUserQuery的流程:- 接收用户ID和时间范围;
- 向读模型(如Elasticsearch的
order_index)发起查询; - 返回预组装好的结果(订单号、商品名称、状态、下单时间)。
- 读模型:通常是非关系型数据库/缓存(如Elasticsearch、Redis、MongoDB),或者数据仓库(如BigQuery)。读模型的结构完全针对查询优化——比如将订单和商品的关联数据预聚合为「宽表」,避免Join操作;或者用全文索引支持模糊查询。
四、简单案例:电商订单系统的CQRS实践
假设我们要设计一个电商订单系统,用CQRS改造前后的对比:
改造前(CRUD):
- 写操作:
Order实体既要处理「创建订单」的库存校验,又要处理「更新订单状态」的物流同步; - 读操作:查询「用户订单历史」时,需要Join
orders、order_items、products三张表,性能随数据量增长急剧下降; - 问题:读流量大时,数据库CPU被Join操作占满,写操作也被阻塞。
改造后(CQRS):
- 写侧:
- Command:
CreateOrderCommand(包含用户ID、商品列表、地址); - Command Handler:校验库存→生成订单→扣减库存→写入MySQL的
orders和order_items表;
- Command:
- 读侧:
- 同步机制:用**Change Data Capture(CDC,变更数据捕获)**工具(如Debezium)监听MySQL的
orders表变更,将数据同步到Elasticsearch的order_index(预聚合商品名称、用户昵称等字段); - Query:
GetOrderHistoryByUserQuery直接查询Elasticsearch,无需Join,响应时间从几百毫秒降到几十毫秒;
- 同步机制:用**Change Data Capture(CDC,变更数据捕获)**工具(如Debezium)监听MySQL的
- 效果:读侧流量完全隔离,写侧保持强一致性,系统吞吐量提升数倍。
五、CQRS的适用场景
CQRS不是银弹,它的价值在于解决「读写需求差异大」的问题,以下场景尤其适合:
- 读多写少的系统:如电商商品详情页、社交平台的Feed流、新闻资讯的列表页;
- 复杂业务逻辑的写操作:如金融系统的转账、电商的订单创建(需要多步校验和事务);
- 多维度复杂查询:如报表系统、数据分析平台(需要聚合多表数据,读模型可以预计算);
- 需要独立扩容的系统:读侧可以单独加Elasticsearch节点,写侧可以单独加MySQL从库,无需整体升级。
六、CQRS+事件溯源(Event Sourcing):用事件记录所有状态
CQRS的写侧如果只更新「当前状态」(比如MySQL的orders表存当前订单状态),会丢失状态变更的历史脉络——比如订单从「待支付」到「已支付」再到「已发货」的过程,传统写模型无法追溯每一步的原因。而事件溯源(Event Sourcing)的出现,就是让写模型用「事件日志」代替当前状态,彻底记录所有变更历史。
1. 事件溯源的核心逻辑
- 事件(Event):不可变的事实记录,描述系统状态的一次变更(如
OrderCreatedEvent「订单创建」、OrderPaidEvent「订单支付」、OrderShippedEvent「订单发货」)。
事件的特点:过去时(已经发生的事实)、包含上下文(如OrderPaidEvent要包含订单ID、支付金额、支付时间、支付渠道)。 - 事件存储(Event Store):专门存储事件的数据库(如Axon Server、EventStoreDB),支持按聚合根(Aggregate Root)查询事件流(比如查询某个订单的所有事件)。
- 聚合根(Aggregate Root):领域驱动设计(DDD)中的概念,是一组相关实体的根节点(如订单是
Order聚合根,包含OrderItem子实体)。事件溯源中,聚合根的状态完全由其事件流重建——比如要得到订单的当前状态,只需从事件存储中查询该订单的所有事件,按顺序重放即可。
2. CQRS+事件溯源的架构
当CQRS结合事件溯源后,写侧的流程会发生变化:
[客户端] → 发送Command → [Command Handler] → 加载聚合根的事件流 → 重放事件得到当前状态 → 执行命令(生成新事件) → 保存新事件到事件存储 → 发布事件到消息队列 → [读侧同步]具体例子(订单系统):
- 客户端发送
PayOrderCommand(订单ID=123,支付金额=100元); - Command Handler从事件存储中加载订单123的所有事件(
OrderCreatedEvent、OrderItemAddedEvent); - 重放这些事件,得到订单当前状态:「待支付」、总金额100元;
- 校验支付金额是否匹配总金额(业务规则);
- 生成
OrderPaidEvent(订单ID=123,支付金额=100元,支付时间=2025-07-24); - 将
OrderPaidEvent保存到事件存储(不可修改); - 发布
OrderPaidEvent到Kafka; - 读侧的同步服务监听Kafka中的
OrderPaidEvent,更新Elasticsearch的order_index(将订单状态从「待支付」改为「已支付」)。
3. 为什么要结合事件溯源?
- 完整的审计日志:所有状态变更都有迹可循,适合金融、医疗等需要合规的系统;
- 状态回溯:可以重放事件流,得到任意时间点的系统状态(比如查询订单在2025-07-20的状态);
- 解耦写侧逻辑:Command Handler只需生成事件,无需直接更新数据库,简化了写侧的复杂度;
- 支持事件驱动架构:事件可以被多个读侧服务消费(比如
OrderPaidEvent可以触发库存扣减、物流通知、用户积分增加等操作)。
七、读写模型的同步机制:如何保证数据一致性?
CQRS的核心矛盾是写模型和读模型的一致性——写侧更新后,读侧需要多久能看到最新数据?常见的同步方式有两种:同步同步和异步同步。
1. 同步同步(Sync Replication)
- 逻辑:写侧执行Command后,立即同步更新读模型,再返回客户端成功。
- 流程:
- Command Handler更新写模型(MySQL);
- 直接调用读侧的更新接口(如向Elasticsearch插入文档);
- 所有操作成功后,返回客户端。
- 优点:读模型实时一致,适合对一致性要求极高的场景(如金融系统的账户余额查询);
- 缺点:写操作的延迟会增加(因为要等读侧更新完成),系统吞吐量下降,且读侧故障会导致写操作失败。
2. 异步同步(Async Replication)
- 逻辑:写侧执行Command后,异步通知读侧更新,立即返回客户端成功。读侧通过消息队列或CDC工具接收变更,最终达到一致。
- 常见实现方式:
- 方式1:事件驱动(Event-Driven):写侧发布事件到消息队列(如Kafka、RabbitMQ),读侧订阅事件并更新读模型(如Elasticsearch);
- 方式2:CDC(变更数据捕获):用工具(如Debezium、Canal)监听写模型的数据库日志(如MySQL的binlog),将变更同步到读模型。
- 例子: 写侧更新MySQL的
orders表→Debezium捕获binlog中的update事件→将事件发送到Kafka→读侧服务消费Kafka事件→更新Elasticsearch的order_index。 - 优点:写操作延迟低,系统吞吐量高,读侧故障不影响写侧;
- 缺点:读模型存在最终一致性(Eventually Consistent)——写操作完成后,读侧可能需要几毫秒到几秒才能看到最新数据。
3. 如何选择同步方式?
- 选同步:如果业务要求「写后立即能读到」(如用户修改密码后,立即登录必须用新密码),则用同步;
- 选异步:如果业务能接受「短暂的不一致」(如电商订单支付后,订单列表可能延迟1秒显示「已支付」),则用异步(大部分互联网场景都适合)。
八、CQRS的落地挑战:你必须面对的坑
CQRS不是银弹,它会引入新的复杂度,以下是最常见的挑战及解决思路:
1. 最终一致性的处理
- 问题:异步同步下,读侧可能读到旧数据(比如用户支付订单后,立即刷新订单列表还是「待支付」);
- 解决思路:
- 前端提示:在写操作完成后,给用户提示「数据正在同步,稍后刷新可见」;
- 读侧兜底:如果读侧查询到旧数据,可以主动从写模型拉取最新数据(如Elasticsearch查不到时, fallback到MySQL);
- 事件幂等性:确保读侧消费事件时,不会重复更新(比如用事件ID作为唯一标识,避免重复处理)。
2. 系统复杂度上升
- 问题:原本一个CRUD服务,拆成了Command Handler、Query Handler、事件存储、消息队列、读模型等多个组件,开发和运维成本翻倍;
- 解决思路:
- 小范围试点:不要一开始就全系统用CQRS,先在「读多写少、查询复杂」的模块试点(如电商的商品详情页、订单历史);
- 用框架简化:使用CQRS框架(如Axon Framework、MediatR),减少重复代码(比如Command的路由、事件的发布订阅)。
3. 事件溯源的存储压力
- 问题:事件存储会保存所有历史事件,数据量会随时间指数级增长(比如一个订单有10个事件,1亿个订单就是10亿条事件);
- 解决思路:
- 事件压缩:对旧事件进行压缩(比如将某个聚合根的早期事件合并为一个「快照(Snapshot)」,重放时只需加载快照+最新事件);
- 冷数据归档:将超过一定时间的事件(如1年前)归档到低成本存储(如S3),需要时再恢复。
4. 调试难度增加
- 问题:异步流程中,Command→Event→读模型更新的链路很长,出问题时难以追踪(比如订单支付后,读侧没更新,不知道是事件没发布还是读侧没消费);
- 解决思路:
- 全链路追踪:用APM工具(如Jaeger、Zipkin)跟踪每个Command的流转,记录Command ID、事件ID、读侧更新时间;
- 事件审计:在事件中加入
traceId、userId等元数据,方便定位问题(比如查询某个traceId的所有事件,看哪一步出错)。
九、CQRS的最佳实践:避免踩坑的关键
总结生产环境中的经验,以下原则能帮你用对CQRS:
1. Command设计原则
- 命名要明确:用「动词+名词」的形式,比如
CreateOrderCommand而不是OrderCommand; - 只包含必要信息:Command应包含执行命令所需的最小数据(比如
PayOrderCommand只需订单ID、支付金额,不需要用户的地址信息); - 保证幂等性:给Command分配唯一ID(如UUID),写侧通过Command ID去重(比如相同的
PayOrderCommand执行多次,只生成一个OrderPaidEvent)。
2. Query设计原则
- 贴合前端需求:Query的返回结果应直接对应前端的UI组件(比如商品详情页的
GetProductDetailQuery返回标题、价格、图片、库存,无需多余字段); - 避免过度抽象:不要设计通用Query(如
GetAllDataQuery),要针对具体场景(如ListUserOrdersByMonthQuery); - 使用缓存优化:对高频Query(如商品列表),用Redis缓存结果,减少读模型的压力。
3. 存储引擎选择
- 写侧存储:优先选支持事务的关系型数据库(如MySQL、PostgreSQL),如果用事件溯源,选专门的事件存储(如EventStoreDB、Axon Server);
- 读侧存储:根据查询需求选择:
- 多维度查询/全文搜索:Elasticsearch;
- 键值查询/高频缓存:Redis;
- 文档型查询:MongoDB;
- 复杂报表:BigQuery/ClickHouse。
4. 逐步演进,不要一刀切
- 第一步:先分离Command和Query的Handler(用MediatR这样的库),但共享同一个数据库(写侧和读侧用同一个MySQL);
- 第二步:当读压力增大时,将读侧迁移到Elasticsearch,用CDC同步数据;
- 第三步:当写侧业务逻辑复杂时,引入事件溯源,用事件存储代替传统写模型。
十、CQRS的误区:不要为了用而用
最后提醒:CQRS不是必须的,以下场景不要用CQRS:
- 简单CRUD系统:比如内部后台管理系统,读写流量小,业务逻辑简单;
- 对一致性要求极高且无法接受延迟:比如银行转账系统,必须写后立即读一致(此时同步同步的成本可能超过CQRS的收益);
- 团队规模小,缺乏DDD和事件驱动经验:CQRS需要团队理解领域模型、事件、聚合根等概念,否则会越用越乱。
总结:CQRS的本质
CQRS不是技术框架,而是一种设计思想——它让我们重新思考「读写职责」,用分离代替耦合,用针对性优化代替一刀切。它的价值在于:
- 写侧专注「正确性」:用事务、校验、事件保证业务规则不被破坏;
- 读侧专注「效率」:用缓存、反规范化、搜索引擎满足高并发查询;
- 系统更易扩展:读写侧可以独立扩容,应对不同的流量压力。
如果你的系统正面临「读多写少、查询复杂、扩展性不足」的问题,CQRS值得一试——但请记住:先理解问题,再选择工具,不要为了「高大上」而引入不必要的复杂度。
到这里,CQRS的核心内容就讲完了。如果还有具体场景的疑问(比如如何设计事件、如何选择CDC工具),可以随时问我~